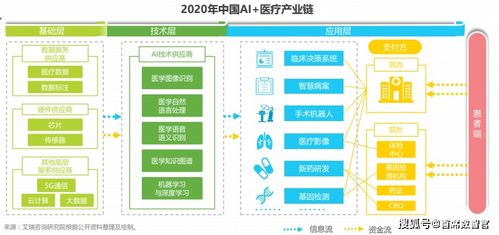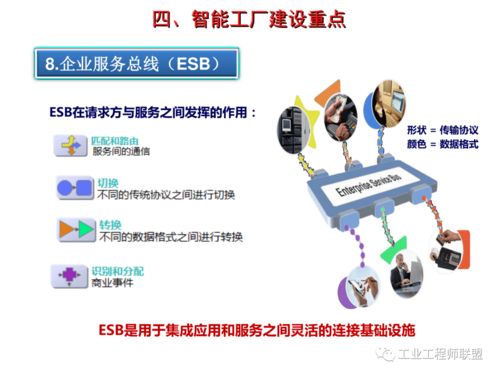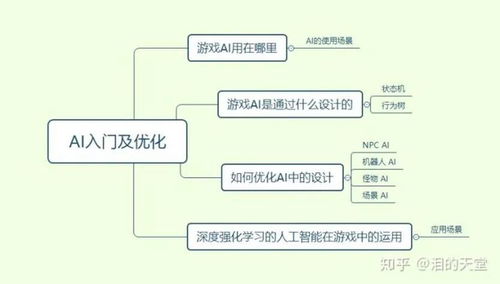
深度強化學習:游戲AI的革命性引擎
深度強化學習(Deep Reinforcement Learning, DRL)是人工智能領域近年來最具突破性的技術之一,它結合了深度學習的感知能力與強化學習的決策能力。在游戲領域,DRL已從實驗室走向實際應用,成為驅動下一代游戲AI的核心技術。從經典的雅達利游戲到復雜的即時戰略游戲《星際爭霸II》,DRL智能體通過與環境持續交互、試錯學習,最終達到了超越人類頂級選手的水平。這種“從零開始”的學習范式,不僅展示了AI的巨大潛力,也為游戲開發帶來了全新的可能性——創建出更具適應性、挑戰性和真實感的非玩家角色。
游戲AI入門:從傳統方法到智能體學習
對于希望將AI引入游戲的開發者而言,理解技術演進路徑至關重要。
1. 傳統游戲AI技術
- 有限狀態機(FSM):最基礎、最廣泛使用的技術,通過預定義的狀態和轉換規則控制NPC行為。優點是簡單、直觀、可預測,但缺乏靈活性和適應性。
- 行為樹(Behavior Tree):通過樹狀結構組織決策邏輯,支持更復雜的分層和模塊化設計,提高了可維護性和復用性。
- 尋路算法:如A*算法,用于解決NPC在游戲世界中的移動路徑規劃問題。
2. 現代學習型AI入門
從傳統腳本式AI轉向學習型AI,第一步是建立正確的思維框架:
- 智能體(Agent):您控制的AI實體。
- 環境(Environment):游戲世界,智能體于此交互。
- 狀態(State):環境在某一時刻的描述。
- 動作(Action):智能體可以執行的操作。
- 獎勵(Reward):環境對智能體動作的反饋信號,是驅動學習的“指南針”。
入門實踐建議從簡單的環境開始,例如OpenAI Gym中的經典控制問題(如CartPole),或使用專為游戲AI設計的平臺,如Unity的ML-Agents Toolkit或Google的Dopamine。關鍵是在一個定義清晰、獎勵信號明確的小規模環境中,成功訓練出第一個能完成基本任務的智能體。
AI優化指南:提升性能與體驗的關鍵策略
一個成功的游戲AI不僅要“聰明”,更要高效、穩定且符合游戲設計目標。
1. 算法與模型優化
- 獎勵塑形(Reward Shaping):設計中間獎勵引導智能體學習,避免稀疏獎勵導致的難以學習問題。這是DRL應用中最具“藝術性”的一環,需要緊密結合游戲邏輯。
- 課程學習(Curriculum Learning):讓智能體從簡單任務開始,逐步增加難度,如同人類的學習過程,能顯著加速訓練并提高最終性能。
- 集成與蒸餾:可以訓練多個智能體(集成),或將大模型的知識“蒸餾”到小模型中,在保持性能的同時降低運行時計算開銷。
2. 工程與實踐優化
- 并行化采樣:利用多個環境實例同時收集數據,極大提高數據效率,縮短訓練時間。
- 模型輕量化:針對部署平臺(如手機、主機)優化神經網絡結構,使用量化、剪枝等技術減小模型體積和延遲。
- 人機回環(Human-in-the-loop):在訓練中引入人類示范或反饋,可以更快地校正智能體的不良行為,使其更符合設計意圖。
3. 設計層優化:好AI ≠ 最強AI
- 可控的挑戰性:AI的水平應可動態調整,匹配不同玩家的技能,提供“心流”體驗。
- 行為多樣性:避免模式化,通過引入隨機性或多策略學習,使AI行為難以預測,增加游戲復玩價值。
- 表現力與“欺騙”:有時需要讓AI表現出擬人化的弱點或做出看似“愚蠢”但能提升玩家樂趣的決策。
人工智能基礎軟件開發:構建您的AI工具箱
開發游戲AI不僅需要算法知識,還需要強大的軟件工程能力來構建支撐系統。
1. 核心開發框架與工具鏈
- 深度學習框架:PyTorch和TensorFlow是兩大主流選擇。PyTorch動態圖特性使其在研究和原型開發中更靈活;TensorFlow則在生產部署和移動端支持上有其優勢。
- 強化學習庫:Stable Baselines3, Ray RLlib等高級庫封裝了PPO、DQN等經典算法,讓開發者能更專注于問題本身而非算法實現細節。
- 游戲AI專用平臺:
- Unity ML-Agents:允許在Unity引擎中直接訓練智能體,無縫集成到游戲開發流程。
- Godot Engine:開源引擎,其AI相關生態也在快速發展。
2. 系統架構設計要點
- 訓練與推理分離:訓練系統(通常使用Python)追求靈活與高效,而部署在游戲內的推理系統(可能用C++/C#)必須追求極致的性能和穩定性。兩者通過模型文件(如ONNX格式)銜接。
- 模擬環境構建:創建一個與真實游戲高度一致、但運行速度可能快數十甚至數百倍的“模擬器”用于訓練,是加速迭代的關鍵。
- 可觀測性與調試工具:開發可視化工具來監控智能體的內部狀態(如價值函數、注意力分布)、決策過程和訓練曲線,這對于調試復雜AI行為不可或缺。
3. 邁向生產環境
- 版本控制:不僅控制代碼,也要對模型、超參數、訓練數據和實驗結果進行系統化管理(可使用DVC、MLflow等工具)。
- 持續集成/持續部署(CI/CD):自動化測試訓練流程,確保代碼更改不會破壞現有功能,并能自動將訓練好的模型部署到測試環境。
- 倫理與測試:建立對AI行為的測試規范,防止出現破壞游戲平衡、利用程序漏洞(“鉆空子”)或產生負面社會影響的行為。
未來展望
深度強化學習為游戲AI打開了新世界的大門,從完全自主的游戲角色到動態平衡的游戲系統,再到個性化的游戲內容生成,其應用前景廣闊。技術始終是工具,成功的游戲AI永遠是技術實現與游戲設計智慧的完美結合。對于開發者而言,踏上這段旅程意味著需要同時擁抱機器學習的前沿算法和扎實的軟件工程實踐。從一個小型實驗項目開始,逐步構建起您對智能體、環境和獎勵函數的直覺,最終將創造出能夠真正豐富玩家體驗、充滿驚喜與生命力的游戲人工智能。